|
| ¿Puedes decir cómo se llaman todos estos personajes de videojuegos? Extraído de http://www.sporcle.com/games/OctoKing/name-all-these-video-game-characters |
¿En qué consiste la localización de videojuegos?
El término localización se emplea para toda aquella traducción que se haga de software, películas... y, por supuesto, videojuegos. Es decir, hablamos de localización cuando, además de traducir, tenemos que, primero, adaptar la parte cultural de aquello que estamos traduciendo (la historia, la religión, la geografía, la política, los usos y costumbres...) para, así, conectar con el receptor (jugador, en este caso) y también para evitar problemas derivados de las diferencias culturales; y, segundo, internacionalizarlo, que también repercute en lo dicho anteriormente.
¿Qué características de los videojuegos hay que tener en cuenta al traducir?
Los videojuegos tienen un formato audiovisual que incluye texto, voces, música... Además, son interactivos (es decir, el jugador participa) y juegan con las emociones del jugador (emociones que, por supuesto, hay que mantener al traducir). Asimismo, aunque, en principio, los videojuegos son de ocio, también pueden ser formativos. Por último, suelen ser multiplataforma (el juego está disponible para varias consolas) y tienen un ciclo de vida variable (pueden tener expansiones, nuevos contenidos, contenidos descargables o DLC[1]...).
Por otra parte, los géneros de los videojuegos son muy variados: acción y aventuras, MMORPG(2), FPS(3), deportes (ah, el eterno FIFA...), Hidden Objects (consiste en encontrar determinados objetos en un escenario), plataformas, simulación, infantiles (¡ojo con el lenguaje empleado al traducir!), sociales... También las plataformas son variadas: los hay para consolas, para ordenadores e, incluso, para móviles.
¿A qué retos debe enfrentarse el localizador de videojuegos?
Uno de las más importantes es la falta de contexto: ¿qué estamos traduciendo? En la mayoría de los casos, solo se dispone de un documento Excel para trabajar: ¿quién habla?, ¿con quién?, ¿dónde hablan?, ¿qué está sucediendo en ese momento?... La falta de contexto, precisamente, es la que hace que se traduzcan palabras de una forma que, digámoslo así, no pega nada en el videojuego... Siempre tendremos de referencia la famosísima traducción del Final Fantasy VII... Recuerdo el trabajo que hicimos durante la carrera y lo mucho que aprendimos haciéndolo: a pesar de que la traducción contenga muchos errores, hay que ponerse en la piel del que lo tradujo, puesto que es muy posible que no supiera muy bien qué estaba pasando en el videojuego porque desconocía su contexto:
 |
| Una de mis favoritas, sin duda. Extraída de Proyecto Allé voy (incluso el nombre del blog hace referencia a otra metedura de pata de la traducción...) |
Otro de los retos más importantes del traductor de videojuegos son las variables, que se encuentran en el texto que se va a traducir. Estas variables hay que dejarlas tal cual en la traducción, ya que indican determinados objetos, lugares, nombres... y es código que debe reconocer el juego. De todas formas, para más información, recomiendo dos entradas del blog Algo más que traducir, El truco del almendruco para las variables en localización y Etiquetas en la localización de videojuegos.
Asimismo, precisamente debido a la falta de contexto y también a que suelen traducirse textos no terminados (es decir, se van enviado a los localizadores para que vayan traduciendo, aunque el juego no esté todavía terminado), no suele haber coherencia en la traducción, lo que hace la tarea realmente difícil.
Finalmente, otro gran problema es la restricción de caracteres: ¿cómo puedes traducir una oración inglesa de, por ejemplo, 10 palabras, a otra española de exactamente 10 palabras (¡o menos!)? Aunque no sea tan restrictivo, sí que es verdad que se impone un límite, ya que debe insertarse en un determinado espacio. Además, si no se respeta (o si no se ha indicado), el texto puede solaparse.
¿Con qué herramientas cuenta el localizador de videojuegos?
Algunas de las herramientas que ayudan a hacer frente a estos retos son los glosarios de los fabricantes (como Sony, Microsoft o Nintendo), que siempre, siempre, siempre hay que respetar, las guías de estilo (que se hacen para cada juego y ayudan a darle coherencia), los diccionarios en línea, las búsquedas en internet, el log de preguntas (mediante el que se hacen preguntas al cliente para solucionar problemas o dudas de la traducción), las memorias de traducción y las bases de datos terminológicas.
¿Qué contenidos debe traducir el localizador?
Aparte, obviamente, del propio videojuego, hay una serie de contenidos que lo rodean, como el material promocional (el tráiler, la caja, la publicidad...), de gran importancia para dar a conocer el juego y que exige una gran creatividad por parte del traductor, creatividad que tiene un límite de espacio, y una coherencia con respecto al juego.
También está el manual del juego; huelga decir que también el traductor tiene que ser coherente con el juego en cuanto a la terminología. Por ejemplo, si el manual le dijera al jugador que tiene que ir a buscar a la tripulación del Resistencia, a este le costaría a costar adivinar que se trata de la tripulación del Endurance...
 |
| Aquí tenemos una captura de la guía de estrategia de uno de los juegos de Tomb Raider. Al menos, aquí contamos con imágenes... |
Finalmente, también hay que escribir una guía de estilo y traducir un glosario(4), que deberá tomarse siempre como referencia a la hora de traducir el juego (y si hay más juegos de la misma serie, con más motivo) para que este sea coherente. En muchas ocasiones, este glosario habrá que realizarlo antes de la traducción o durante el proceso de traducción; para ello, habrá que seleccionar aquellas palabras que, por su frecuente aparición, consideremos términos.
 |
| Un ejercicio de clase fue intentar traducir los nombres de las criaturas del juego Ni no Kuni... Todo un reto. |
Otros aspectos
Finalmente, hay algunos otros aspectos que son importantes en la localización de videojuegos. Uno es lo que se conoce como ingame, es decir, los textos en pantalla, como los menús, los botones, los indicadores, el código intercalado (por ejemplo, <...>, /n o [LB]), variables (como %s, %d, %@, o {item_name} No hay consenso y en cada juego pueden aparecer de una manera distinta, pero se identifican fácilmente)...
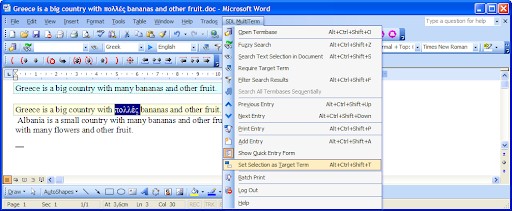
A propósito del texto en pantalla y de las variables, tengo esta captura de pantalla de mis apuntes del curso, para la que creo que no hace falta más explicaciones:
 |
| Captura de pantalla de mis apuntes del curso de Localización de videojuegos de Cálamo&Cran sobre las variables. |
 |
| Entonces... ¿Cait Sith es chico o chica? Extraído de Proyecto Allé Voy. |
En primer lugar, si se trata de diálogos anidados, lo cual supone una gran dificultad. Este tipo de diálogos aparecen en juegos como las aventuras gráficas y es el jugador el que va eligiendo la respuesta que va a dar a sus interlocutores en cada momento. Además, el otro personaje responderá en función de lo que se le haya dicho... Todo esto hace que sea muy difícil seguir la línea argumental a la hora de traducir.
Como ejemplo, se me ocurre un videojuego del manga Fushigi Yûgi que no salió de Japón y en el que, como muchos juegos del género otome, tienes una serie de personajes masculinos que son amigos tuyos (o no) y, al final, terminas ligándote a uno en función de las decisiones que hayas tomado a lo largo del juego... Pero, para ofrecer un ejemplo más normalito, pondré una imagen del maravilloso juego de Beyond: Dos almas, en el que, en función de las opciones que elijas, desbloquearás un final u otro... Hay que decir que no sería el ejemplo más representativo de la dificultad de la traducción de diálogos anidados, porque las respuestas de los interlocutores no se basan demasiado en lo que dice la protagonista (sino que, más bien, lo que cambia es la acción, el desarrollo del videojuego)... Aun así, creo que representa bien lo que son las tomas de decisiones en los videojuegos y lo importante que es traducirlas bien:
 |
| Captura del videojuego Beyond: Two Souls. ¿Podríamos conseguir que la traducción española no fuera mucho más extensa? Quizá, sí... Extraído de http://wac.450f.edgecastcdn.net/80450F/arcadesushi.com/files/2013/10/Beyond-Two-Souls-5.jpg |
En segundo lugar, también puede tratarse de cadenas propagadas, esto es, de frases que se ponen en boca de distintos personajes. Como estos personajes pueden tener distintas edades, sexos..., es conveniente optar por una traducción neutra, lo que es, sin embargo, bastante difícil en muchos casos.
No consigo encontrar una captura, pero recuerdo el Pokemon Edición Cristal cuando, por primera vez, podías elegir entre chico o chica para el protagonista y claro, los diálogos cambiaban un poco. Cuando escapabas de un combate pokemon, decía "¡Escapaste sin problemas!", en vez del anterior "Escapaste sano y salvo": es una estupenda manera de evitar la marca de género. En ediciones posteriores, ya se adaptaría, supongo, el código del juego (muchas veces, el juego no está preparado para hacer distinción de género en las palabras y el traductor no puede hacer mucho para solventar este problema), por lo que se traduciría de manera distinta.
Finalmente, hay que tener en cuenta si lo que estamos traduciendo (localizando) son subtítulos o si se va a utilizar para el doblaje. Esto se da en las secuencias de vídeo o cinemáticas y, como sucede en las películas, no es lo mismo si se está traduciendo para el doblaje (en cuyo caso, hay que adaptarlo al movimiento de los labios del personaje) o solo para un subtítulo (en ese caso, habría que intentar simplificar un poco las oraciones para que al jugador no le resulte excesivamente farragoso).
Sea el caso que sea, habrá que tener siempre en cuenta los problemas mencionados anteriormente, entre los que se encuentra nuestra querida restricción de caracteres.
¿En conclusión?
Para dar fin a esta extensísima entrada (gracias a los que me hayáis leído hasta el final o, al menos, con atención e interés), diré que el curso de Localización de videojuegos que hice en Cálamo&Cran me ha venido estupendamente para mi formación como traductora. Además, he aprendido muchísimo con respecto al proceso de localización y esto ha hecho aumentar mi interés y mis ganas por dedicarme a ello.
Espero que esta entrada os sirva y que os haya parecido útil. Para terminar, me gustaría recomendar un (¡otro!) curso en línea sobre videojuegos que ahora estoy haciendo y que me ha servido como complemento al curso de localización de videojuegos, Diseño, organización y evaluación de videojuegos y gamificación, organizado por la Universidad Europea de Madrid y que se imparte en la plataforma de MOOC Miríadax. Aunque no cubre el tema de la localización de videojuegos, sí habla de todo el proceso de creación de videojuegos, desde sus inicios hasta el momento en el que se pone a la venta, pasando por la publicidad, las personas que trabajan en él, la crítica de videojuegos...
Espero que esta entrada os sirva y que os haya parecido útil. Para terminar, me gustaría recomendar un (¡otro!) curso en línea sobre videojuegos que ahora estoy haciendo y que me ha servido como complemento al curso de localización de videojuegos, Diseño, organización y evaluación de videojuegos y gamificación, organizado por la Universidad Europea de Madrid y que se imparte en la plataforma de MOOC Miríadax. Aunque no cubre el tema de la localización de videojuegos, sí habla de todo el proceso de creación de videojuegos, desde sus inicios hasta el momento en el que se pone a la venta, pasando por la publicidad, las personas que trabajan en él, la crítica de videojuegos...
_________________________________________________________________________________
(1) DLC son las siglas inglesas de Donwloadable Content ('contenido descargable')
(2) MMORPG es una sigla inglesa formada por RPG (Role Playing Game, 'juego de rol') y MMO (Massively Multiplayer Online, 'multijugador masivo en línea').
(3) FPS es la sigla, también inglesa, de First Person Shooter ('disparos en primera persona').
(4) Dicho glosario puede ser heredado (es decir, se envía al localizador ya preparado y traducido, para así mantener la coherencia entre las series del mismo juego) o, en el caso de que se envíe el glosario sin saber de qué va el juego o incluso sin estar traducido, estático (una vez traducido, ya será inamovible) o flexible (podrán ir haciéndose cambios sobre la marcha).